打算系统性地学习和复习一下字符串算法。
一些算法内容比较多会拆到别的文章里。
首先让我们形式化地定义一下字符串的各个概念。
字符集 为一个建立了全序关系的集合,用符号 Σ \Sigma Σ 字符 。
Tip: 有些时候全序关系不是必须的。
字符串 s s s
下文默认字符串下标从 1 1 1
定义 s i s_i s i s s s i i i
定义 ∣ s ∣ \left|s\right| ∣ s ∣ s s s
空串 即为不包含任何字符,∣ s ∣ = 0 \left|s\right| = 0 ∣ s ∣ = 0
我们定义字符与字符、字符与字符串、字符串与字符、字符串与字符串之间的拼接 表示将这两个字符或字符串按顺序拼在一起得到的字符串,写作 s + t s + t s + t s t st s t s k s^k s k k k k s s s
字符串 s s s 子串 s [ l , r ] s_{[l, r]} s [ l , r ] s l , s l + 1 , … s r s_l, s_{l + 1}, \ldots s_{r} s l , s l + 1 , … s r s l + s l + 1 + … s r s_l + s_{l + 1} + \ldots s_r s l + s l + 1 + … s r [ l , r ] = ∅ [l, r] = \varnothing [ l , r ] = ∅ s s s 子序列 是由 s s s
字符串 s s s 后缀 为从某个位置 i i i s s s s u f ( s , i ) \mathrm{suf}(s, i) s u f ( s , i ) s u f ( s , i ) = s [ i , ∣ s ∣ ] \mathrm{suf}(s, i) = s_{[i, |s|]} s u f ( s , i ) = s [ i , ∣ s ∣ ] 真后缀 为不是其本身的后缀,空串为任意字符串的后缀。s s s 前缀 为从 s s s i i i p r e ( s , i ) \mathrm{pre}(s, i) p r e ( s , i ) p r e ( s , i ) = s [ 1 , i ] \mathrm{pre}(s, i) = s_{[1, i]} p r e ( s , i ) = s [ 1 , i ]
字典序 :以第 i i i i i i s 1 s_1 s 1 s 2 s_2 s 2 s 1 < s 2 s_1 < s_2 s 1 < s 2
回文串(Palindrome String) 为满足 ∀ 1 ≤ i ≤ ∣ s ∣ , s i = s ∣ s ∣ − i + 1 \forall 1 \le i \le \left|s\right|, s_i = s_{\left|s\right| - i + 1} ∀ 1 ≤ i ≤ ∣ s ∣ , s i = s ∣ s ∣ − i + 1
对于给定的若干个字符串,我们构建出一棵有根树,这棵树有如下性质:
每条边上有一个边权,是一个字符。
每个点向儿子连的边的边权互不相同。
按顺序拼接从根到某个点的路径上的边权,得到的串一定是给出的字符串中某些串的前缀。
根到叶子的路径对应的串一定是某个给出的串。
例如:对于字符串 aa,aba,ba,caaa,cab,cba,cc,我们可以构造出如下的树:
(图源 OI Wiki)
这棵树被称为 Trie。
考虑如何构造 Trie。
具体地,每次从根开始遍历,并同时维护该字符串当前的字符,如果当前点已经有该字符的儿子,就直接走过去,否则新建一个节点。
1 2 3 4 5 6 7 8 9 void insert (string s) int now = 0 ; for (char c : s) { int id = c - 'a' ; if (!trie[now][id]) trie[now][id] = ++tot; now = trie[now][id]; } return ; }
Trie 的大小是 O ( ∑ s ) O(\sum s) O ( ∑ s ) O ( n ) O(n) O ( n )
Trie 的基本应用是查询某个串是否在给出的字典中出现过或查询某个串是字典中多少串的前缀。
要实现如上操作需要在每个节点上维护以该点为前缀的串的个数以及该点是否为给出的串。
对 Trie 的先序遍历可以实现字符串排序。
Trie 的本质是一个接受且仅接受给定串的自动机。
可以将整数视为定长的二进制串然后构建 Trie,这种 Trie 被称为 01Trie,由于其拥有非常优秀的树形结构因此常被用来维护与二进制操作相关的信息,由于与字符串关系不大因此这里略去不讲。
例题:[NEERC2016] Binary Code
给定 n n n 0 或 1,求是否存在一种方案,使得任意一个字符串都不是其他串的前缀。若有解则输出方案。
1 ≤ n ≤ 5 × 1 0 5 1 \le n \le 5\times 10^5 1 ≤ n ≤ 5 × 1 0 5 5 × 1 0 5 5\times 10^5 5 × 1 0 5
TL: 2s, ML: 1GB
考虑两个串 s i , s j s_i, s_j s i , s j s i s_i s i s j s_j s j
问题是如果两两比较连边的话复杂都是 O ( n 2 ) O(n^2) O ( n 2 )
由于是前缀关系,考虑建出 Trie 树。对于每个串,将两种填法都加到 Trie 中,这样两个点之间有边当且仅当他们是祖先关系,发现树边刚好可以满足这点限制,直接拿来用好了。
实际实现时需要注意一些细节。
link
对于一个字符串 s s s z ( i ) z(i) z ( i ) s s s s u f ( s , i ) \mathrm{suf}(s, i) s u f ( s , i ) 最长公共前缀 (Longest Common Prefix, LCP)的长度。特别地,z ( 1 ) = 0 z(1) = 0 z ( 1 ) = 0
显然求 Z 函数有一个朴素的 O ( ∣ s ∣ 2 ) O(|s|^2) O ( ∣ s ∣ 2 )
假设我们已经求出 z ( 1 ) , z ( 2 ) , … , z ( i − 1 ) z(1), z(2), \ldots, z(i - 1) z ( 1 ) , z ( 2 ) , … , z ( i − 1 ) z ( i ) z(i) z ( i ) j + z ( j ) j + z(j) j + z ( j ) i < j + z ( j ) i < j + z(j) i < j + z ( j ) s [ i , j + z ( j ) ) = s [ i − j + 1 , z ( j ) ] s_{[i, j + z(j))} = s_{[i - j + 1, z(j)]} s [ i , j + z ( j ) ) = s [ i − j + 1 , z ( j ) ] z ( i ) ≥ min { z ( i − j + 1 ) , j + z ( j ) − i } z(i) \ge \min\{z(i - j + 1), j + z(j) - i\} z ( i ) ≥ min { z ( i − j + 1 ) , j + z ( j ) − i } z ( i ) z(i) z ( i )
看起来好像只是优化了常数?实际上若 i ≥ j + z ( j ) i \ge j + z(j) i ≥ j + z ( j ) j + z ( j ) − i ≤ z ( i − j + 1 ) j + z(j) - i \le z(i - j + 1) j + z ( j ) − i ≤ z ( i − j + 1 ) j + z ( j ) j + z(j) j + z ( j ) 1 1 1 i < j + z ( j ) i < j + z(j) i < j + z ( j ) j + z ( j ) − i > z ( i − j + 1 ) j + z(j) - i > z(i - j + 1) j + z ( j ) − i > z ( i − j + 1 ) z ( i ) = z ( i − j + 1 ) z(i) = z(i - j + 1) z ( i ) = z ( i − j + 1 ) O ( ∣ s ∣ ) O(|s|) O ( ∣ s ∣ )
参考代码如下:
1 2 3 4 5 6 for (int i = 2 , j = 0 ; i <= n; i++) { if (i < j + z[j]) z[i] = min (z[i - j + 1 ], j + z[j] - i); while (i + z[i] <= n && s[i + z[i]] == s[1 + z[i]]) z[i]++; if (i + z[i] > j + z[j]) j = i; }
如果你学过 SA 你会发现 Z 函数能求的东西 SA 都能求,所以 Z 函数屁用没有。
Z 函数可以用来加速字符串比较,比较常见的应用是在 DP 中优化时间复杂度,或者纯粹拿来求 LCP。
例题 1:NOIP2020 字符串匹配
给你一个字符串 s s s s s s ( A B ) k C (AB)^kC ( A B ) k C A A A C C C
多组数据,1 ≤ T ≤ 5 , 1 ≤ ∣ s ∣ ≤ 2 20 1 \le T \le 5, 1 \le |s| \le 2^{20} 1 ≤ T ≤ 5 , 1 ≤ ∣ s ∣ ≤ 2 2 0
TL: 1s, ML: 512MB.
考虑枚举 ∣ A B ∣ |AB| ∣ A B ∣ k k k ⌊ z ( ∣ A B ∣ + 1 ) + ∣ A B ∣ ∣ A B ∣ ⌋ \lfloor\frac{z(|AB| + 1) + |AB|}{|AB|}\rfloor ⌊ ∣ A B ∣ z ( ∣ A B ∣ + 1 ) + ∣ A B ∣ ⌋
然后再考虑字符个数的限制,显然我们只要知道 C C C A B AB A B
容易发现 A B A B ABAB A B A B C C C k k k k k k C C C s u f ( s , ∣ A B ∣ + 1 ) \mathrm{suf}(s, |AB| + 1) s u f ( s , ∣ A B ∣ + 1 ) k k k C C C
然后就做完了,时间复杂度 O ( T ∣ s ∣ ∣ Σ ∣ ) O(T|s||\Sigma|) O ( T ∣ s ∣ ∣ Σ ∣ )
例题 2:ARC058F 文字列大好きいろはちゃん
给 n n n k k k
1 ≤ n ≤ 2000 , 1 ≤ k ≤ 1 0 4 1 \le n \le 2000, 1 \le k \le 10^4 1 ≤ n ≤ 2 0 0 0 , 1 ≤ k ≤ 1 0 4 1 0 6 10^6 1 0 6
TL: 5s, ML: 750MB.
考虑朴素 DP:设 d p i , j dp_{i, j} d p i , j i i i j j j O ( n k 2 ) O(nk^2) O ( n k 2 )
先对于每个 i , j i, j i , j d p i , j dp_{i, j} d p i , j i i i m − j m - j m − j j < k j < k j < k d p i , j dp_{i, j} d p i , j d p i , k dp_{i, k} d p i , k i i i i i i
然后考虑转移,按 j j j d p i , j dp_{i, j} d p i , j d p i − 1 , j dp_{i - 1, j} d p i − 1 , j d p i − 1 , j − ∣ s i ∣ dp_{i - 1, j - |s_i|} d p i − 1 , j − ∣ s i ∣ d p i , j dp_{i, j} d p i , j
考虑用一个单调栈维护有效状态,比较当前最长的串和 d p i , j dp_{i, j} d p i , j
若是 d p i , j dp_{i, j} d p i , j d p i , j dp_{i, j} d p i , j
若比 d p i , j dp_{i, j} d p i , j d p i , j dp_{i, j} d p i , j
若比 d p i , j dp_{i, j} d p i , j d p i , j dp_{i, j} d p i , j
考虑这个过程中我们要支持什么串的比较,显然用到的所有串都是上一轮的最长串的某个前缀接上 s i s_i s i O ( 1 ) O(1) O ( 1 )
时间复杂度 O ( n k + ∑ ∣ s i ∣ ) O(nk + \sum |s_i|) O ( n k + ∑ ∣ s i ∣ )
Manacher 用于求一个字符串 s s s
长度为偶数的回文子串的回文中心是两个字符,比较难搞,考虑用一些方法将它变成长度为奇数的串。
对于字符串 s = s 1 s 2 s 3 … s n s = s_1 s_2 s_3 \ldots s_n s = s 1 s 2 s 3 … s n # s 1 # s 2 # s 3 # … # s n # \#s_1\#s_2\#s_3\#\ldots\#s_n\# # s 1 # s 2 # s 3 # … # s n # # \# # s s s # \# # p p p ⌊ p 2 ⌋ \lfloor\frac{p}{2}\rfloor ⌊ 2 p ⌋
朴素暴力就是直接来。考虑用类似 Z 函数的方法优化。设 p j p_j p j j j j p 1 , p 2 , p 3 , … , p i − 1 p_1, p_2, p_3, \ldots, p_{i - 1} p 1 , p 2 , p 3 , … , p i − 1 j + p j j + p_j j + p j j j j i ≤ j + p j i \le j + p_j i ≤ j + p j p i ≥ min { p 2 j − i , j + p j − i + 1 } p_i \ge \min\{p_{2j - i}, j + p_j - i + 1\} p i ≥ min { p 2 j − i , j + p j − i + 1 } p i p_i p i
时间复杂度分析和 Z 函数类似,读者自证不难,这里不再赘述。
注意实现时一般在两端添加另外两个特殊字符以防止越界。
1 2 3 4 5 6 7 8 9 string s = "^#" ; for (char i : t) s.push_back (i), s.push_back ('#' );s.push_back ('@' ); for (int i = 1 , j = 0 ; i <= 2 * n + 1 ; i++) { if (i <= j + p[j]) p[i] = min (p[2 * j - i], j + p[j] - i); while (s[i - p[i] - 1 ] == s[i + p[i] + 1 ]) p[i]++; if (i + p[i] > j + p[j]) j = i; }
例题:PKUSC2024 Day1T1 回文路径
给定一个 2 × n 2\times n 2 × n
1 ≤ n ≤ 1 0 5 1 \le n \le 10^5 1 ≤ n ≤ 1 0 5
TL: 1s, ML: 512MB.
先求出只在某一行的最长回文子串,然后考虑在某个地方拐弯。
如果拐弯要不劣于不拐弯,那么容易得出如果在 p p p p + 1 p + 1 p + 1 p p p
容易发现此时等价于在回文串右端点拐弯,因此对于每个原本的回文串,有唯一确定的拐点。之后就直接二分哈希即可。
咕。
尽量在不引入计算理论的情况下解释自动机的用处。因此会讲得比较简略且不太会设计正则语言相关内容。
在讲自动机之前,我们需要先了解以下定义:
定义一个字母表 (alphabet)是一个非空有限集合,用 Σ \Sigma Σ 符号 / 字符 (symbol)。
字符串 是字母表中的元素构成的有穷序列。特别地,用 ε \varepsilon ε 0 0 0 我们定义两个字符串 a , b a, b a , b 连接 为 a b ab a b a a a b b b
记所有长度为 n n n Σ n \Sigma ^ n Σ n Σ 0 = { ε } \Sigma ^ 0 = \{\varepsilon\} Σ 0 = { ε } Σ ∗ = ⋃ i = 0 ∞ Σ i \Sigma ^ * = \bigcup _ {i = 0} ^ \infty \Sigma ^ i Σ ∗ = ⋃ i = 0 ∞ Σ i Σ \Sigma Σ 语言 (language)是 Σ ∗ \Sigma ^ * Σ ∗ L L L
与 OI 中常见的定义稍有不同。
确定性有限状态自动机 (Deterministic finite automaton, DFA)可以被形式化地定义为一个五元组 ( Σ , Q , q 0 , F , δ ) (\Sigma, Q, q_0, F, \delta) ( Σ , Q , q 0 , F , δ )
Σ \Sigma Σ Q Q Q q 0 ∈ Q q_0 \in Q q 0 ∈ Q F ⊆ Q F \subseteq Q F ⊆ Q δ : Q × Σ → Q \delta: Q \times \Sigma \to Q δ : Q × Σ → Q
若将状态看作点,转移函数看作有向边,则可以直观地将一个自动机画成一张状态图。在状态图中,一般用一个没有起点的箭头指向起始状态,用同心圆表示终止状态。
对于一个字符串 s = s 1 s 2 … s n s = s_1s_2\ldots s_n s = s 1 s 2 … s n M = ( Σ , Q , q 0 , F , δ ) M = (\Sigma, Q, q_0, F, \delta) M = ( Σ , Q , q 0 , F , δ ) r 0 , r 1 , … , r n r_0, r_1, \ldots, r_n r 0 , r 1 , … , r n
r 0 = q 0 r_0 = q_0 r 0 = q 0 ∀ 1 ≤ i ≤ n , δ ( r i − 1 , s i ) = r i \forall 1 \le i \le n, \delta(r_{i - 1}, s_i) = r_i ∀ 1 ≤ i ≤ n , δ ( r i − 1 , s i ) = r i r n ∈ F r_n \in F r n ∈ F
则称这个自动机可以接受该字符串。
对于自动机 M M M M M M L ( M ) L(M) L ( M ) M M M L ( M ) L(M) L ( M )
如果一个语言可以被一个 DFA 识别,则称这个语言为正则语言 。
与 DFA 类似,非确定性有限状态自动机 (Non-deterministic Finite Automaton, NFA)也可以被形式化地定义为一个五元组 ( Σ , Q , q 0 , F , δ ) (\Sigma, Q, q_0, F, \delta) ( Σ , Q , q 0 , F , δ )
Σ \Sigma Σ Q Q Q q 0 ∈ Q q_0 \in Q q 0 ∈ Q F ⊆ Q F \subseteq Q F ⊆ Q δ : Q × Σ → 2 Q \delta: Q \times \Sigma \to 2^Q δ : Q × Σ → 2 Q
与 DFA 唯一不同的地方在于转移函数。
NFA 可以接受一个字符串的条件也与 DFA 类似,只需把第二条改为 r i ∈ δ ( r i − 1 , s i ) r_i \in \delta(r_{i - 1}, s_i) r i ∈ δ ( r i − 1 , s i )
NFA-ε \varepsilon ε ε \varepsilon ε δ : Q × Σ ∪ { ε } → 2 Q \delta: Q \times \Sigma \cup \{\varepsilon\} \to 2^Q δ : Q × Σ ∪ { ε } → 2 Q u u u δ ( u , ε ) \delta(u, \varepsilon) δ ( u , ε ) ε \varepsilon ε
看起来 NFA 相较 DFA 能识别更多的语言,NFA-ε \varepsilon ε
Tip: 称两个自动机等价,当且仅当它们能识别的语言相同。
定理 1:对于任意一个 NFA-ε \varepsilon ε
对于 NFA-ε \varepsilon ε ε \varepsilon ε
更形式化地说就是,对于原 NFA-ε \varepsilon ε q q q c c c
δ ′ ( q , c ) = δ ( q , c ) ∪ δ ( δ ( q , ε ) , c ) ∪ δ ( δ ( δ ( q , ε ) , ε ) , c ) ∪ ⋯ \delta'(q, c) = \delta(q, c) \cup \delta(\delta(q, \varepsilon), c) \cup \delta(\delta(\delta(q, \varepsilon), \varepsilon), c) \cup \cdots
δ ′ ( q , c ) = δ ( q , c ) ∪ δ ( δ ( q , ε ) , c ) ∪ δ ( δ ( δ ( q , ε ) , ε ) , c ) ∪ ⋯
即可。
定理 2:对于任意一个 NFA,都可以找到一个等价的 DFA。
将 NFA 转化成 DFA 的算法被称为子集构造法。
算法实现流程如下:
将初始状态加入到 DFA 中但不标记。
每次取出 DFA 中一个未被标记的状态,加上标记。
将其转移设为其对应的 NFA 中的状态集合的转移的并对应的状态。
若某个转移到的状态未被加入则加入 DFA 但不标记。
重复 2 到 4 步直到所有状态都被标记。
正确性显然。但是这样构造出来的 DFA 的状态数是指数级别的。
因此如果要判断一个串能否被一个 NFA 识别,如果直接将其转化成 DFA 则复杂度会变成指数级。
一种简单的实现方式是转移时记录所有可能到达的状态,这样单次转移复杂度是状态数平方级别的。
显然可以通过 bitset 优化转移。
另外还可以使用四毛子来优化。将 NFA 的状态分块,设大小为 T T T 2 T 2^T 2 T
分析一下复杂度,是 O ( ∣ Q ∣ 2 2 T ∣ Σ ∣ T ω + n ∣ Q ∣ 2 T ω ) O(\frac{|Q|^2 2^T |\Sigma|}{T \omega} + \frac{n |Q|^2}{T \omega}) O ( T ω ∣ Q ∣ 2 2 T ∣ Σ ∣ + T ω n ∣ Q ∣ 2 ) T = log n ∣ Σ ∣ T = \log \frac{n}{|\Sigma|} T = log ∣ Σ ∣ n O ( n ∣ Q ∣ 2 ω log n ∣ Σ ∣ ) O(\frac{n |Q|^2}{\omega \log\frac{n}{|\Sigma|}}) O ( ω l o g ∣ Σ ∣ n n ∣ Q ∣ 2 )
将一个 DFA 转化为与它等价且状态数最少的 DFA,使用 Hopcroft 算法。
首先去除所有无法从 q 0 q_0 q 0 F F F
我们定义两个状态 u , v u, v u , v
[ u ∈ F ] = [ v ∈ F ] [u \in F] = [v \in F] [ u ∈ F ] = [ v ∈ F ] ∀ c ∈ Σ \forall c \in \Sigma ∀ c ∈ Σ δ ( u , c ) \delta(u, c) δ ( u , c ) δ ( v , c ) \delta(v, c) δ ( v , c )
Hopcroft 的基本思想是先将所有状态按是否是接受状态划分成两个等价类,然后每次取出一个等价类 S S S u , v ∈ S , c ∈ Σ u, v \in S, c \in \Sigma u , v ∈ S , c ∈ Σ δ ( u , c ) \delta(u, c) δ ( u , c ) δ ( v , c ) \delta(v, c) δ ( v , c ) S S S S S S
这样操作后将所有等价类作为新 DFA 的一个状态即可。显然这个 DFA 中不存在两个不可区分的状态。可以证明不存在不可区分的状态的 DFA 是最小的。证明可以参考:https://zh.wikipedia.org/wiki/迈希尔-尼罗德定理 。
直接实现应该是平方还立方的,太慢了。一种优化方式是:
维护一个集合表示还没被考虑过的等价类的集合 W W W X X X c c c Y Y Y c c c X X X A , B A, B A , B Y Y Y A , B A, B A , B W W W W W W
为什么只需要放入小的那个?不妨假设放入的是 A A A B B B Y Y Y Y Y Y B B B A A A A A A
这样的时间复杂度就是 O ( ∣ Σ ∣ ∣ Q ∣ log ∣ Q ∣ ) O(|\Sigma||Q| \log |Q|) O ( ∣ Σ ∣ ∣ Q ∣ log ∣ Q ∣ )
可以构造 DFA 以识别某些特定的语言。
例题:CF1142D Foreigner
定义一个数 x x x
x x x 1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 , 9 1, 2, 3, 4, 5, 6, 7, 8, 9 1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 , 9 ⌊ x 10 ⌋ \lfloor\frac{x}{10}\rfloor ⌊ 1 0 x ⌋ ⌊ x 10 ⌋ \lfloor\frac{x}{10}\rfloor ⌊ 1 0 x ⌋ k k k 1 1 1 x m o d 10 < k m o d 11 x \bmod 10 < k \bmod 11 x m o d 1 0 < k m o d 1 1
给你一个由数码构成的字符串 s s s
1 ≤ ∣ s ∣ ≤ 1 0 5 1 \le |s| \le 10^5 1 ≤ ∣ s ∣ ≤ 1 0 5
TL: 1s, ML: 256MB.
观察条件,可以发现除 1 ∼ 9 1\sim 9 1 ∼ 9
具体地,若一个牛的数 x x x k k k 10 x ∼ 10 x + k m o d 11 − 1 10x \sim 10x + k \bmod 11 - 1 1 0 x ∼ 1 0 x + k m o d 1 1 − 1 x ′ = 10 x + c ( 0 ≤ c < k m o d 11 ) x' = 10x + c (0 \le c < k \bmod 11) x ′ = 1 0 x + c ( 0 ≤ c < k m o d 1 1 ) x ′ x' x ′ k ′ k' k ′
k ′ = 9 + ∑ i = 1 k − 1 ( i m o d 11 ) + c + 1 k' = 9 + \sum\limits_{i = 1}^{k - 1} (i \bmod 11) + c + 1
k ′ = 9 + i = 1 ∑ k − 1 ( i m o d 1 1 ) + c + 1
观察发现:
0 + 1 + 2 + … + 10 = 55 ≡ 0 ( m o d 11 ) 0 + 1 + 2 + \ldots + 10 = 55 \equiv 0 \pmod{11}
0 + 1 + 2 + … + 1 0 = 5 5 ≡ 0 ( m o d 1 1 )
所以我们只需要知道 k m o d 11 k \bmod 11 k m o d 1 1
基于这点,我们可以构造一个只接受牛的数的 DFA:
{ Σ = { 0 , 1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 , 9 } Q = { q 0 , 0 , 1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 , 9 , 10 } F = Q ∖ { q 0 } δ ( u , c ) = { c u = s , c ≠ 0 ( 10 + ∑ i = 0 u − 1 i + c ) m o d 11 u ≠ s , c < u \left\{
\begin{aligned}
& \Sigma = \{0, 1, 2, 3, 4, 5, 6, 7, 8, 9\} \\
& Q = \{q_0, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10\} \\
& F = Q \setminus \{q_0\} \\
& \delta(u, c) = \begin{cases}
c & u = s, c \ne 0 \\
(10 + \sum_{i = 0}^{u - 1} i + c) \bmod 11 & u \ne s, c < u
\end{cases}
\end{aligned}
\right.
⎩ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎨ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎧ Σ = { 0 , 1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 , 9 } Q = { q 0 , 0 , 1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 , 9 , 1 0 } F = Q ∖ { q 0 } δ ( u , c ) = { c ( 1 0 + ∑ i = 0 u − 1 i + c ) m o d 1 1 u = s , c = 0 u = s , c < u
设 d p i , u dp_{i, u} d p i , u s s s i i i u u u
最终答案即为 ∑ i = 1 ∣ s ∣ ∑ u = 0 10 d p i , u \sum_{i = 1}^{|s|} \sum_{u = 0}^{10} dp_{i, u} ∑ i = 1 ∣ s ∣ ∑ u = 0 1 0 d p i , u
另一个应用是 DP 套 DP。对于一个 DP,可以将其 DP 状态视为自动机的状态,把 DP 变成一个自动机的形式。这样在计数满足某些限制条件的串时,就可以先设计一个用来判断串是否满足条件的 DP,然后在由这个 DP 构造的自动机上计数。
实际上就是将上面的手动构造自动机变成了用 DP 状态来表示自动机。
例题:「TJOI2018」游园会
给你一个长度为 k k k { N , O , I } \{\texttt{N}, \texttt{O}, \texttt{I}\} { N , O , I } t t t n n n { N , O , I } \{\texttt{N}, \texttt{O}, \texttt{I}\} { N , O , I } s s s s s s t t t i i i NOI \texttt{NOI} NOI i i i
1 ≤ n ≤ 1000 , 1 ≤ k ≤ 15 1 \le n \le 1000, 1 \le k \le 15 1 ≤ n ≤ 1 0 0 0 , 1 ≤ k ≤ 1 5
TL: 6s, ML: 250MB.
设要满足 LCS 为 m m m
考虑对于确定串计算 LCS:f i , j = max { f i − 1 , j , f i , j − 1 , f i − 1 , j − 1 + [ s i = t j ] } f_{i, j} = \max\{f_{i - 1, j}, f_{i, j - 1}, f_{i - 1, j - 1} + [s_i = t_j]\} f i , j = max { f i − 1 , j , f i , j − 1 , f i − 1 , j − 1 + [ s i = t j ] }
这个串合法当且仅当 f n , k = m f_{n, k} = m f n , k = m
我们以 f i , 1 … k f_{i, 1\ldots k} f i , 1 … k s s s f k = m f_k = m f k = m t t t m m m
记 d p i , s dp_{i, s} d p i , s i i i s s s
唯一的问题就是自动机的状态数太多。观察上面的 DP 方程,容易发现 f j f_j f j 1 1 1 2 k 2^k 2 k
注意,某些 DP 套 DP 题的自动机状态数可能会比较大,此时需要用 DFA 最小化算法减少状态数。
子序列自动机是一个只能接受某个字符串 s s s
考虑设 0 0 0 i i i p r e ( s , i ) \mathrm{pre}(s, i) p r e ( s , i ) p r e ( s , i − 1 ) \mathrm{pre}(s, i - 1) p r e ( s , i − 1 ) i i i s s s i i i
{ Q = { x ∈ N ∣ 0 ≤ x ≤ ∣ s ∣ } q 0 = 0 F = Q δ ( u , c ) = min { i ∣ i > u , s i = c } \left\{
\begin{aligned}
& Q = \{x \in \mathbb{N} \mid 0 \le x \le |s|\} \\
& q_0 = 0 \\
& F = Q \\
& \delta(u, c) = \min\{i \mid i > u, s_i = c\}
\end{aligned}
\right.
⎩ ⎪ ⎪ ⎪ ⎪ ⎪ ⎨ ⎪ ⎪ ⎪ ⎪ ⎪ ⎧ Q = { x ∈ N ∣ 0 ≤ x ≤ ∣ s ∣ } q 0 = 0 F = Q δ ( u , c ) = min { i ∣ i > u , s i = c }
具体构建时,只需要从后往前遍历,维护每个字符的最后一次出现的位置即可。时间复杂度为 O ( ∣ s ∣ ∣ Σ ∣ ) O(|s||\Sigma|) O ( ∣ s ∣ ∣ Σ ∣ )
这样构建出来的子序列自动机满足每个子序列在自动机上经过的点对应其在原串上第一次出现的位置。
KMP 是一个接受所有以模式串 s s s
具体来说就是考虑 KMP 匹配的过程,然后建成自动机:
{ Q = { x ∈ N ∣ 0 ≤ x ≤ ∣ s ∣ } q 0 = 0 F = { ∣ s ∣ } δ ( u , c ) = { u + 1 u < ∣ s ∣ ∧ s u + 1 = c δ ( π u , c ) u = ∣ s ∣ ∨ ( u > 0 ∧ s u + 1 ≠ c ) 0 u = 0 ∧ s u + 1 ≠ c \left\{
\begin{aligned}
& Q = \{x \in \mathbb{N} \mid 0 \le x \le |s|\} \\
& q_0 = 0 \\
& F = \{|s|\} \\
& \delta(u, c) = \begin{cases}
u + 1 & u < |s| \land s_{u + 1} = c \\
\delta(\pi_u, c) & u = |s| \lor (u > 0 \land s_{u + 1} \ne c) \\
0 & u = 0 \land s_{u + 1} \ne c
\end{cases}
\end{aligned}
\right.
⎩ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎨ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎧ Q = { x ∈ N ∣ 0 ≤ x ≤ ∣ s ∣ } q 0 = 0 F = { ∣ s ∣ } δ ( u , c ) = ⎩ ⎪ ⎪ ⎨ ⎪ ⎪ ⎧ u + 1 δ ( π u , c ) 0 u < ∣ s ∣ ∧ s u + 1 = c u = ∣ s ∣ ∨ ( u > 0 ∧ s u + 1 = c ) u = 0 ∧ s u + 1 = c
构建考虑从前往后加字符,发现若当前长度为 n n n c c c π n + 1 = δ ( n , c ) \pi_{n + 1} = \delta(n, c) π n + 1 = δ ( n , c ) O ( 1 ) O(1) O ( 1 ) O ( ∣ s ∣ ∣ Σ ∣ ) O(|s||\Sigma|) O ( ∣ s ∣ ∣ Σ ∣ )
例题:CF1721E Prefix Function Queries
给定一个字符串 s s s q q q t i t_i t i i i i s + t i s + t_i s + t i ∣ t i ∣ |t_i| ∣ t i ∣
1 ≤ ∣ s ∣ ≤ 1 0 6 , 1 ≤ q ≤ 1 0 5 , 1 ≤ ∣ t i ∣ ≤ 10 1 \le |s| \le 10^6, 1 \le q \le 10^5, 1 \le |t_i| \le 10 1 ≤ ∣ s ∣ ≤ 1 0 6 , 1 ≤ q ≤ 1 0 5 , 1 ≤ ∣ t i ∣ ≤ 1 0
TL: 2s, ML: 250MB.
KMP 自动机,每次从 ∣ s ∣ |s| ∣ s ∣
KMP 自动机的主要优势在于复杂度不基于均摊,因此可以支持一些可持久化操作等均摊复杂度错误的东西。
一组模式串的 AC 自动机是一个接受所有以某个模式串为后缀的串的自动机。
看起来是 KMP 自动机的强化版,考虑用类似的思路去构建。
首先对于模式串建出 Trie。令 Q Q Q q 0 q_0 q 0 F F F f a i l i fail_i f a i l i i i i
若我们可以求出 fail 指针,则可以得到其转移函数:
δ ( u , c ) = { t r i e u , c t r i e u , c = n u l l δ ( f a i l u , c ) u ≠ q 0 ∧ t r i e u , c = n u l l q 0 t r i e u , c = n u l l \delta(u, c) = \begin{cases}
trie_{u, c} & trie_{u, c} = \mathrm{null} \\
\delta(fail_u, c) & u \ne q_0 \land trie_{u, c} = \mathrm{null} \\
q_0 & trie_{u, c} = \mathrm{null}
\end{cases}
δ ( u , c ) = ⎩ ⎪ ⎪ ⎨ ⎪ ⎪ ⎧ t r i e u , c δ ( f a i l u , c ) q 0 t r i e u , c = n u l l u = q 0 ∧ t r i e u , c = n u l l t r i e u , c = n u l l
这里 t r i e u , c trie_{u, c} t r i e u , c u u u c c c n u l l \mathrm{null} n u l l
现在的问题就是怎么求 fail。
与 KMP 自动机类似,可以发现 f a i l t r i e u , c = δ ( f a i l u , c ) fail_{trie_{u, c}} = \delta(fail_u, c) f a i l t r i e u , c = δ ( f a i l u , c )
容易发现 f a i l u fail_u f a i l u u u u
令 n n n m m m O ( m + n ∣ Σ ∣ ) O(m + n|\Sigma|) O ( m + n ∣ Σ ∣ )
参考代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 struct ACAM { int tot, fail[200005 ], delta[200005 ][26 ]; void insert (string s, int id) int now = 0 ; for (char c : s) { int v = c - 'a' ; if (!delta[now][v]) delta[now][v] = ++tot; now = delta[now][v]; } return ; } void build () queue<int > q; for (int c = 0 ; c < 26 ; c++) if (delta[0 ][c]) q.push (delta[0 ][c]); while (!q.empty ()) { int now = q.front (); q.pop (); for (int c = 0 ; c < 26 ; c++) if (delta[now][c]) fail[delta[now][c]] = delta[fail[now]][c], q.push (delta[now][c]); else delta[now][c] = delta[fail[now]][c]; } return ; } } ac;
对于 AC 自动机上每个点 u ≠ q 0 u \ne q_0 u = q 0 u u u f a i l u fail_u f a i l u q 0 q_0 q 0
fail 树上每个点的父亲都是该串的最长真后缀,是一个比较优秀的性质,很多题目可以将问题放在 fail 树上考虑然后变成树上问题。
例如:AC 自动机的一个经典应用——多模式串字符串匹配:给你一个文本串和若干模式串,求出每个模式串在文本串中的出现次数。
首先对模式串建出 AC 自动机,然后用文本串在自动机上跑。任意时刻,当前节点及其所有在 fail 树上的祖先对应的串都是当前扫到的文本串的后缀。也就是说每次走到一个节点 u u u u u u 1 1 1
例题 1:CCPC 2021 Guilin H. Popcount Words
定义 w ( l , r ) = s l s l + 1 … s r w(l, r) = s_l s_{l + 1} \ldots s_r w ( l , r ) = s l s l + 1 … s r s i s_i s i p o p c o u n t ( i ) m o d 2 \mathrm{popcount}(i) \bmod 2 p o p c o u n t ( i ) m o d 2
给定 n n n [ l i , r i ] [l_i, r_i] [ l i , r i ] S S S
S = w ( l 1 , r 1 ) + w ( l 2 , r 2 ) + ⋯ + w ( l n , r n ) S = w(l_1, r_1) + w(l_2, r_2) + \cdots + w(l_n, r_n)
S = w ( l 1 , r 1 ) + w ( l 2 , r 2 ) + ⋯ + w ( l n , r n )
q q q p p p p p p S S S
1 ≤ n , q ≤ 1 0 5 , 1 ≤ l i ≤ r i ≤ 1 0 9 , ∑ ∣ p ∣ ≤ 5 × 1 0 5 1 \le n, q \le 10^5, 1 \le l_i \le r_i \le 10^9, \sum |p| \le 5\times 10^5 1 ≤ n , q ≤ 1 0 5 , 1 ≤ l i ≤ r i ≤ 1 0 9 , ∑ ∣ p ∣ ≤ 5 × 1 0 5
TL: 1s, ML: 512MB.
p o p c o u n t ( i ) m o d 2 \mathrm{popcount}(i) \bmod 2 p o p c o u n t ( i ) m o d 2
{ 0 , 1 , 1 , 0 , 1 , 0 , 0 , 1 , … } \{0, 1, 1, 0, 1, 0, 0, 1, \ldots\}
{ 0 , 1 , 1 , 0 , 1 , 0 , 0 , 1 , … }
这个序列有个名字叫 Thue-Morse 序列 。有一些比较显然的性质:
可以按如下方式倍增构造:{ 0 } \{0\} { 0 } { 0 } → { 0 , 1 } → { 0 , 1 , 1 , 0 } → ⋯ \{0\} \to \{0, 1\} \to \{0, 1, 1, 0\} \to \cdots { 0 } → { 0 , 1 } → { 0 , 1 , 1 , 0 } → ⋯
取出其任意一个长度为 k k k O ( log k ) O(\log k) O ( log k ) 2 2 2 T i , 0 / 1 T_{i, 0 / 1} T i , 0 / 1 2 i 2^i 2 i 2 i 2^i 2 i
基于这些性质,我们首先可以把 S S S O ( n log n ) O(n\log n) O ( n log n )
对询问串建出 AC 自动机,然后设 f i , j , 0 / 1 f_{i, j, 0 / 1} f i , j , 0 / 1 i i i T j , 0 / 1 T_{j, 0 / 1} T j , 0 / 1 f f f
然后在 AC 自动机上跑 S S S g i , j , 0 / 1 g_{i, j, 0 / 1} g i , j , 0 / 1 i i i T j , 0 / 1 T_{j, 0 / 1} T j , 0 / 1 O ( n log n ) O(n\log n) O ( n log n )
然后从大到小枚举 j j j g i , j , 0 / 1 g_{i, j, 0 / 1} g i , j , 0 / 1 g i , j − 1 , 0 / 1 , g t o i , j − 1 , 0 / 1 , j − 1 , 1 / 0 g_{i, j - 1, 0 / 1}, g_{to_{i, j - 1, 0 / 1}, j - 1, 1 / 0} g i , j − 1 , 0 / 1 , g t o i , j − 1 , 0 / 1 , j − 1 , 1 / 0
最后拆到 j = 0 j = 0 j = 0
例题 2:洛谷 P8147 [JRKSJ R4] Salieri
给出 n n n s i s_i s i v i v_i v i m m m S S S k k k c n t i cnt_i c n t i s i s_i s i S S S c n t i × v i cnt_i\times v_i c n t i × v i k k k
1 ≤ n , m ≤ 1 0 5 , ∑ i = 1 n ∣ s i ∣ ≤ 5 × 1 0 5 , ∑ ∣ S ∣ ≤ 5 × 1 0 5 1 \le n, m \le 10^5, \sum_{i = 1}^n |s_i| \le 5 \times 10^5, \sum |S| \le 5 \times 10^5 1 ≤ n , m ≤ 1 0 5 , ∑ i = 1 n ∣ s i ∣ ≤ 5 × 1 0 5 , ∑ ∣ S ∣ ≤ 5 × 1 0 5
TL: 2s, ML: 256MB.
考虑二分答案,然后变成求 c n t i × v i ≥ l i m cnt_i\times v_i \ge lim c n t i × v i ≥ l i m
先对 s i s_i s i c n t i cnt_i c n t i
显然在 AC 自动机上经过的点的个数为 ∣ S ∣ |S| ∣ S ∣ c n t i cnt_i c n t i c n t × w i ≥ l i m ⟺ w i ≥ ⌈ l i m c n t ⌉ cnt \times w_i \ge lim \iff w_i \ge \lceil\frac{lim}{cnt}\rceil c n t × w i ≥ l i m ⟺ w i ≥ ⌈ c n t l i m ⌉
例题 3:The 2020 ICPC Asia Macau Regional Contest B. Boring Problem
给 n n n k k k m m m t i t_i t i k k k p i p_i p i ∑ i = 1 k p i = 1 \sum_{i = 1}^k p_i = 1 ∑ i = 1 k p i = 1
对于一个字符集为前 k k k S S S
若存在一个串 t i t_i t i S S S
以 p i p_i p i i i i S S S
定义 f ( S , t , p ) f(S, t, p) f ( S , t , p ) S S S R R R 1 ≤ i ≤ ∣ R ∣ 1 \le i \le |R| 1 ≤ i ≤ ∣ R ∣ f ( p r e ( R , i ) , t , p ) f(\mathrm{pre}(R, i), t, p) f ( p r e ( R , i ) , t , p ) 1 0 9 + 7 10^9 + 7 1 0 9 + 7
1 ≤ n ≤ 100 , 1 ≤ n × m ≤ 1 0 4 , 1 ≤ k ≤ 26 , 1 ≤ ∣ R ∣ ≤ 1 0 4 1 \le n \le 100, 1 \le n\times m \le 10^4, 1 \le k \le 26, 1 \le |R| \le 10^4 1 ≤ n ≤ 1 0 0 , 1 ≤ n × m ≤ 1 0 4 , 1 ≤ k ≤ 2 6 , 1 ≤ ∣ R ∣ ≤ 1 0 4
TL: 1s, ML: 512MB.
考虑建出 AC 自动机,问题就是对于 AC 自动机求从某个点出发随机游走到接受状态的期望步数。
直接高斯消元是 O ( n 3 m 3 + ∣ R ∣ ) O(n^3 m^3 + |R|) O ( n 3 m 3 + ∣ R ∣ )
注意到 AC 自动机的 Trie 上只有 n n n
于是考虑能否只设出 n n n u u u u u u u u u u u u
因此直接 bfs,只需要设出轻儿子和根总共 n n n 0 0 0 n n n O ( n 3 + n 2 m + ∣ R ∣ ) O(n^3 + n^2m + |R|) O ( n 3 + n 2 m + ∣ R ∣ )
回文树是一个用来维护某个串上所有回文子串的结构,因为拥有自动机结构又被称为回文自动机 (Palindromic Automaton)。
显然自动机是无法识别“回文串”这种非正则语言的,即使是一个串的回文子串这种有限的语言,想要处理也比较有难度。因此我们不妨暂时抛开“自动机”而是先去考虑“树”这个结构。
考虑回文串的定义,维护整个串似乎过于麻烦且信息冗余,不妨对于每个串只维护其右半部分。我们定义一个回文串从回文中心开始的后缀为这个回文串的半串 。那么,我们可以简单地将回文树描述成这些回文子串的半串的 Trie。
但是这又涉及在 Manacher 时遇到的问题:回文串的长度有奇数和偶数。一种解决方法是像 Manacher 一样在相邻两个字符之间插入 #,但是这种方法太过丑陋。更好的方法是直接建两棵树,一棵树中所有节点对应的回文串长度均为奇数,另一棵均为偶数。两棵树的根分别被称为奇根和偶根,我们认为它们分别代表长度为 − 1 -1 − 1 0 0 0 − 2 - 2 − 2
了解完定义后考虑怎么构建 PAM。
与 AC 自动机类似,我们定义节点 u u u u u u
考虑增量构造,假设已经构建了 p r e ( s , p − 1 ) \mathrm{pre}(s, p - 1) p r e ( s , p − 1 ) s p s_p s p
我们考虑从以上一个字符结尾的最长回文子串出发,一直跳 fail,直到当前节点的长度 l e n len l e n s p − l e n − 1 = s p s_{p - len - 1} = s_p s p − l e n − 1 = s p A A A
然后如果 A A A s p s_p s p A A A s p s_p s p
但是先别急,看起来好像每次只增加了以新的字符结尾的最长回文后缀,而没有维护更短的回文后缀。实际上,更短的回文后缀一定出现在之前的串中,因为他被更长的回文串包含,对称一下就对称到前面去了。这同时也说明了一个字符串的本质不同回文子串至多只有长度个,因此其 PAM 的状态数也是线性的。
考虑分析这个东西的复杂度。考虑当前节点在 fail 树上的深度,每次往上跳深度 − 1 -1 − 1 2 2 2 + 2 +2 + 2 + 1 +1 + 1
参考代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 struct PAM { int tot, delta[500005 ][26 ], len[500005 ], fail[500005 ]; string s; int lst; PAM () {tot = 1 ; len[0 ] = 0 ; len[1 ] = -1 ; fail[0 ] = fail[1 ] = 1 ;} int getfail (int now, int i) while (s[i - len[now] - 1 ] != s[i]) now = fail[now]; return now; } void insert (int i) int now = getfail (lst, i); if (!delta[now][s[i] - 'a' ]) { len[++tot] = len[now] + 2 ; fail[tot] = delta[getfail (fail[now], i)][s[i] - 'a' ]; delta[now][s[i] - 'a' ] = tot; } lst = delta[now][s[i] - 'a' ]; return ; } } p;
上面说过,虽然 PAM 长得不那么自动机,但在一定程度上也具有自动机结构。我们可以将它的转移视为在当前字符串的两侧都添加一个相同的字符。
考虑这样一个问题:给定两个串 s , t s, t s , t
我们对 s s s t t t t t t
例题 1:洛谷 P4762 [CERC2014] Virus synthesis
初始有一个空串,利用下面的操作构造给定串 S S S
串开头或末尾加一个字符
串开头或末尾加一个该串的逆串
求最小化操作数。
∣ S ∣ ≤ 1 0 5 |S| \le 10^5 ∣ S ∣ ≤ 1 0 5
TL: 1s~10s, ML: 125MB.
考虑最后一次 2 操作,操作完后会变成一个偶回文串,然后剩下的用 1 1 1
另一个比较重要的观察是所有偶回文的最后一次操作一定是 2 2 2
对 S S S f u f_u f u u u u
f u ← min v 是 u 的半串的子串 f v + ∣ u ∣ 2 − ∣ v ∣ + 1 f u ← f f a u + 1 \begin{aligned}
f_u &\gets \min_{v \text{ 是 } u \text{ 的半串的子串}} f_v + \frac{|u|}{2} - |v| + 1 \\
f_u &\gets f_{fa_u} + 1
\end{aligned}
f u f u ← v 是 u 的半串的子串 min f v + 2 ∣ u ∣ − ∣ v ∣ + 1 ← f f a u + 1
第一个转移是先拼半串的一个子串再补完半串,然后用 2 2 2 2 2 2
优化转移是简单的,第一个转移的条件显然可以变成 v v v u u u v v v
例题 2:BZOJ3103 Palindromic Equivalence
给一个字符串 s s s t t t ∣ t ∣ = ∣ s ∣ |t| = |s| ∣ t ∣ = ∣ s ∣ t t t s s s
∣ s ∣ ≤ 1 0 6 |s| \le 10^6 ∣ s ∣ ≤ 1 0 6
TL: 435ms, ML: 128MB.
考虑怎么样的串是满足条件的,发现建出 PAM,如果两个串的 PAM 同构且每个点所在的位置相同则符合条件。于是有一个直接的想法就是对 s s s
考虑用零类边缩成若干个等价类,然后变成给一张图每个点染色使得相邻点颜色不同。这个显然不可做,于是考虑着一些性质。
大胆猜一下是弦图并且有一个比较阳间的完美消除序列,比如按等价类内最小值从大到小排序。如果猜想正确的话只要从前往后扫一遍直接数就对了。
然后你发现猜对了,考虑怎么证明。
首先你要注意到连边的本质是对于每个极长回文子串 [ l , r ] [l, r] [ l , r ] l + i , r − i l + i, r - i l + i , r − i l − 1 , r + 1 l - 1, r + 1 l − 1 , r + 1
以下用 E 0 , E 1 E_0, E_1 E 0 , E 1
引理一:对于 i < j < k i < j < k i < j < k ( i , k ) , ( j , k ) ∈ E 1 (i, k), (j, k) \in E_1 ( i , k ) , ( j , k ) ∈ E 1 i , j i, j i , j i , j i, j i , j
考虑有回文子串 s [ i + 1 , k − 1 ] , s [ j + 1 , k − 1 ] s_{[i + 1, k - 1]}, s_{[j + 1, k - 1]} s [ i + 1 , k − 1 ] , s [ j + 1 , k − 1 ] s [ i + 1 , i + k − j − 1 ] s_{[i + 1, i + k - j - 1]} s [ i + 1 , i + k − j − 1 ] ( j , i + k − j ) ∈ E 0 (j, i + k - j) \in E_0 ( j , i + k − j ) ∈ E 0 ( i , j ) ∈ E 0 (i, j) \in E_0 ( i , j ) ∈ E 0 ( i , i + k − j ) ∈ E 1 (i, i + k - j) \in E_1 ( i , i + k − j ) ∈ E 1 i , j i, j i , j
引理二:对于同一等价类内的相邻的两个点 i , j i, j i , j ( i , j ) ∈ E 0 (i, j) \in E_0 ( i , j ) ∈ E 0 s [ i , j ] s_{[i, j]} s [ i , j ]
考虑对于 i < j < k i < j < k i < j < k s [ i , k ] , s [ j , k ] s_{[i, k]}, s_{[j, k]} s [ i , k ] , s [ j , k ]
若 j = i + k 2 j = \frac{i + k}{2} j = 2 i + k s [ i , j ] s_{[i, j]} s [ i , j ]
若 j > i + k 2 j > \frac{i + k}{2} j > 2 i + k s [ i , i + k − j ] s_{[i, i + k - j]} s [ i , i + k − j ] s [ i + k − j , j ] s_{[i + k - j, j]} s [ i + k − j , j ] ( i , i + k − j ) , ( i + k − j , j ) ∈ E 0 (i, i + k - j), (i + k - j, j) \in E_0 ( i , i + k − j ) , ( i + k − j , j ) ∈ E 0
若 j < i + k 2 j < \frac{i + k}{2} j < 2 i + k s [ i , i + k − j ] s_{[i, i + k - j]} s [ i , i + k − j ] s [ j , i + k − j ] s_{[j, i + k - j]} s [ j , i + k − j ] k − j k - j k − j
对于 i < j < k i < j < k i < j < k s [ i , k ] , s [ i , j ] s_{[i, k]}, s_{[i, j]} s [ i , k ] , s [ i , j ]
因此,对于等价类内任意相邻两个点之间的路径 p 1 , p 2 , … , p n p_1, p_2, \ldots, p_n p 1 , p 2 , … , p n p i < p i + 1 > p i + 2 p_i < p_{i + 1} > p_{i + 2} p i < p i + 1 > p i + 2 p i > p i + 1 < p i + 2 p_i > p_{i + 1} < p_{i + 2} p i > p i + 1 < p i + 2 p i , p i + 1 , p i + 2 p_i, p_{i + 1}, p_{i + 2} p i , p i + 1 , p i + 2 p i p_i p i p i + 2 p_{i + 2} p i + 2
用 m n ( x ) mn(x) m n ( x ) x x x i , j , u , v i, j, u, v i , j , u , v
( i , u ) , ( j , v ) ∈ E 1 (i, u), (j, v) \in E_1 ( i , u ) , ( j , v ) ∈ E 1 u , v u, v u , v m n ( i ) < m n ( u ) , m n ( j ) < m n ( u ) mn(i) < mn(u), mn(j) < mn(u) m n ( i ) < m n ( u ) , m n ( j ) < m n ( u )
都满足 i i i j j j
考虑此时有两个回文串,对于其中任意一个,不妨设其是 s [ a + 1 , b − 1 ] s_{[a + 1, b - 1]} s [ a + 1 , b − 1 ] a = min ( i , u ) , b = max ( i , u ) a = \min(i, u), b = \max(i, u) a = min ( i , u ) , b = max ( i , u ) b b b b b b c c c s [ c , b ] s_{[c, b]} s [ c , b ] a a a c c c
若 c < a c < a c < a c + b − a c + b - a c + b − a a a a a ← c + b − a , b ← c a \gets c + b - a, b \gets c a ← c + b − a , b ← c
若 c > a c > a c > a s [ c + 1 , b − 1 ] s_{[c + 1, b - 1]} s [ c + 1 , b − 1 ] s [ a + 1 , a + b − c − 1 ] s_{[a + 1, a + b - c - 1]} s [ a + 1 , a + b − c − 1 ] a + b − c a + b - c a + b − c b b b b ← a + b − c b \gets a + b - c b ← a + b − c
重复以上操作直到无法操作,此时必然有 u = m n ( u ) , i < u u = mn(u), i < u u = m n ( u ) , i < u
对于 j , v j, v j , v v = m n ( v ) , j < v v = mn(v), j < v v = m n ( v ) , j < v
此时根据引理一,i i i j j j
证毕。
例题 3:The 1st Universal Cup, Stage 1: Shenyang H. P-P-Palindrome
给出 n n n s 1 , s 2 , … , s n s_1, s_2, \ldots, s_n s 1 , s 2 , … , s n
我们定义双倍回文为形式 P Q PQ P Q P P P Q Q Q s i s_i s i P , Q P, Q P , Q s i s_i s i P Q PQ P Q
当 P P P Q Q Q P Q PQ P Q
1 ≤ n , ∑ i = 1 n ∣ s i ∣ ≤ 1 0 6 1 \le n, \sum_{i = 1}^n |s_i| \le 10^6 1 ≤ n , ∑ i = 1 n ∣ s i ∣ ≤ 1 0 6
TL: 3s, ML: 512MB.
先找性质。不妨设 ∣ P ∣ < ∣ Q ∣ |P| < |Q| ∣ P ∣ < ∣ Q ∣ Q Q Q P P P Q Q Q n n n 2 2 2 1 1 1
然后考虑拼起来是回文串的限制,也就是要 p r e ( Q , ∣ Q ∣ − ∣ P ∣ ) \mathrm{pre}(Q, |Q| - |P|) p r e ( Q , ∣ Q ∣ − ∣ P ∣ ) i i i p r e ( Q , i ) , s u f ( Q , i + 1 ) \mathrm{pre}(Q, i), \mathrm{suf}(Q, i + 1) p r e ( Q , i ) , s u f ( Q , i + 1 ) p r e ( Q , i ) , s u f ( Q , i + 1 ) \mathrm{pre}(Q, i), \mathrm{suf}(Q, i + 1) p r e ( Q , i ) , s u f ( Q , i + 1 ) Q Q Q i , ∣ Q ∣ − i i, |Q| - i i , ∣ Q ∣ − i Q Q Q gcd ( i , ∣ Q ∣ − i ) \gcd(i, |Q| - i) g cd( i , ∣ Q ∣ − i ) Q Q Q Q Q Q i i i Q Q Q Q Q Q p p p 2 ⋅ ∣ Q ∣ p − 1 2 \cdot \frac{|Q|}{p} - 1 2 ⋅ p ∣ Q ∣ − 1
对于 n = 1 n = 1 n = 1 n > 1 n > 1 n > 1
例题 4:洛谷 P5433 月宫的符卡序列
给一个字符串 S S S 0 0 0
对于一个字符串 T T T T T T T T T S S S
中点的定义为,如果 T = S [ l … r ] T=S[l \ldots r] T = S [ l … r ] ⌊ l + r 2 ⌋ \lfloor\frac{l+r}{2}\rfloor ⌊ 2 l + r ⌋
求 S S S 回文 子串的最大价值。
t t t
1 ≤ ∣ S ∣ ≤ 1 0 6 , 1 ≤ t ≤ 5 1 \le |S| \le 10^6, 1 \le t \le 5 1 ≤ ∣ S ∣ ≤ 1 0 6 , 1 ≤ t ≤ 5
TL: 1s, ML: 125MB.
由于 PAM 的形式与后缀树类似,其也具有与后缀树类似的性质:每个节点对应的回文串的出现位置(e n d p o s \mathrm{endpos} e n d p o s
因此我们只需对每个极长回文子串维护其出现位置及对应在 PAM 上的节点即可。
求极长回文子串需要 Manacher,然后考虑怎么维护这个串在 PAM 上的位置,哈希一下就好了。
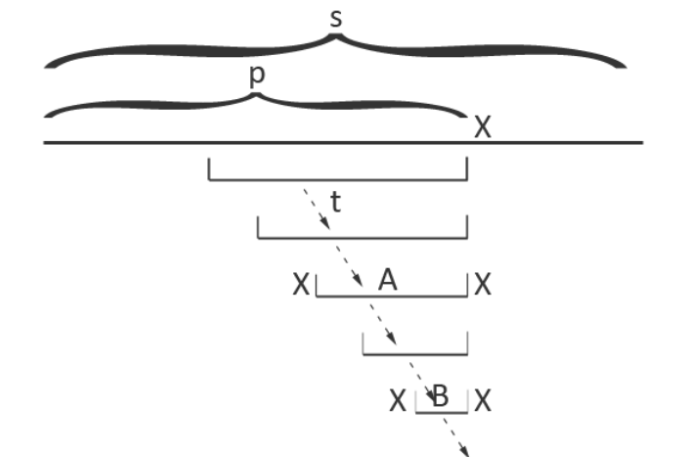
讲后缀自动机之前首先要讲一下 e n d p o s \mathrm{endpos} e n d p o s
对于字符串 s s s t t t e n d p o s ( t ) \mathrm{endpos}(t) e n d p o s ( t ) s s s t t t e n d p o s ( t ) = { x ∣ s x − ∣ t ∣ + 1 , x = t } \mathrm{endpos}(t) = \left\{x \mid s_{x - \left|t\right| + 1, x} = t\right\} e n d p o s ( t ) = { x ∣ s x − ∣ t ∣ + 1 , x = t }
我们会发现对于某些子串可能会出现 e n d p o s \mathrm{endpos} e n d p o s e n d p o s \mathrm{endpos} e n d p o s
性质 1:一个等价类里的所有子串一定是其中最长的子串的连续的后缀。
原因显然。
我们定义一个等价类中最长的子串为该等价类的代表元。
性质 2:一个等价类中的子串 t t t
显然。
性质 3:对于任意两个非空子串 u , v ( ∣ u ∣ ≤ ∣ v ∣ ) u, v (\left|u\right| \le \left|v\right|) u , v ( ∣ u ∣ ≤ ∣ v ∣ ) e n d p o s ( v ) ⊆ e n d p o s ( u ) \mathrm{endpos}(v) \subseteq \mathrm{endpos}(u) e n d p o s ( v ) ⊆ e n d p o s ( u ) e n d p o s ( u ) ∩ e n d p o s ( v ) = ∅ \mathrm{endpos}(u) \cap \mathrm{endpos}(v) = \varnothing e n d p o s ( u ) ∩ e n d p o s ( v ) = ∅
因为若 e n d p o s ( u ) \mathrm{endpos}(u) e n d p o s ( u ) e n d p o s ( v ) \mathrm{endpos}(v) e n d p o s ( v ) u u u v v v
为了方便叙述,下文中用 l e n \mathrm{len} l e n e n d p o s ( 空串 ) = ∅ \mathrm{endpos}(\text{空串}) = \varnothing e n d p o s ( 空串 ) = ∅
我们定义一个等价类的 l i n k \mathrm{link} l i n k l e n \mathrm{len} l e n l i n k \mathrm{link} l i n k l i n k \mathrm{link} l i n k
性质 1:如果将等价类视为一个点,每个等价类的 l i n k \mathrm{link} l i n k
原因显然:每个点只有一个出边,且最终都指向虚拟等价类,且虚拟等价类没有出边。
我们称之为后缀链接树 ,或 parent tree 。
性质 2:每个等价类的 e n d p o s \mathrm{endpos} e n d p o s e n d p o s \mathrm{endpos} e n d p o s s s s
每个等价类的元素一定是该等价类的儿子的元素的后缀。且对于任意非前缀的子串,其每次出现一定会对应某个以其为后缀的子串出现。
终于要来力!
SAM 是一个接受 s s s 最小的 DFA。s s s δ ( p , c ) \delta(p, c) δ ( p , c ) p p p c c c e n d p o s \mathrm{endpos} e n d p o s
在所有满足上述条件的自动机中,SAM 是最小的。
性质 1:从起始状态出发,到达某一状态,按顺序记录下经过的转移的字符,其构成 s s s s s s
性质 2:从起始状态出发到达某一状态的所有路径构成的字符串就是该等价类中的字符串。
以下文字直接读可能有点难以理解,建议配合画 SAM 工具 理解。 如果你突然读不懂了或者感觉哪里不是很显然,不妨回去看看 e n d p o s \mathrm{endpos} e n d p o s l i n k \mathrm{link} l i n k
SAM 的构建是在线的。
假设我们已经构建好了 p r e ( s , i − 1 ) \mathrm{pre}(s, i - 1) p r e ( s , i − 1 ) p r e ( s , i ) \mathrm{pre}(s, i) p r e ( s , i )
不妨令 c = s i c = s_i c = s i
显然添加进 c c c p r e ( s , i ) \mathrm{pre}(s, i) p r e ( s , i ) u u u p r e ( s , i − 1 ) \mathrm{pre}(s, i -1) p r e ( s , i − 1 ) l a s t last l a s t l e n ( u ) = l e n ( l a s t ) + 1 \mathrm{len}(u) = \mathrm{len}(last) + 1 l e n ( u ) = l e n ( l a s t ) + 1
考虑添加进 c c c p r e ( s , i − 1 ) \mathrm{pre}(s, i - 1) p r e ( s , i − 1 ) l a s t last l a s t l i n k \mathrm{link} l i n k
设我们当前跳到的状态为 p p p δ ( p , c ) \delta(p, c) δ ( p , c )
若 δ ( p , c ) = n u l l \delta(p, c) = \mathrm{null} δ ( p , c ) = n u l l p p p δ ( p , c ) = u \delta(p, c) = u δ ( p , c ) = u δ ( p , c ) = n u l l \delta(p, c) = \mathrm{null} δ ( p , c ) = n u l l p r e ( s , i ) \mathrm{pre}(s, i) p r e ( s , i ) u u u l i n k ( u ) = s t a r t \mathrm{link}(u) = start l i n k ( u ) = s t a r t
否则,我们设 q = δ ( p , c ) q = \delta(p, c) q = δ ( p , c ) l e n ( q ) = l e n ( p ) + 1 \mathrm{len}(q) = \mathrm{len}(p) + 1 l e n ( q ) = l e n ( p ) + 1 q q q p p p c c c q q q l i n k \mathrm{link} l i n k l i n k ( u ) = q \mathrm{link}(u) = q l i n k ( u ) = q u u u p r e ( s , i ) \mathrm{pre}(s, i) p r e ( s , i )
若 l e n ( q ) > l e n ( p ) + 1 \mathrm{len}(q) > \mathrm{len}(p) + 1 l e n ( q ) > l e n ( p ) + 1 s i − l e n ( p ) , i s_{i - \mathrm{len}(p), i} s i − l e n ( p ) , i q q q s i − l e n ( p ) , i s_{i - \mathrm{len}(p), i} s i − l e n ( p ) , i e n d p o s \mathrm{endpos} e n d p o s i i i q q q e n d p o s \mathrm{endpos} e n d p o s v v v
l e n ( v ) = l e n ( p ) + 1 \mathrm{len}(v) = \mathrm{len}(p) + 1 l e n ( v ) = l e n ( p ) + 1 原先 q q q
l i n k ( q ) = v \mathrm{link}(q) = v l i n k ( q ) = v l i n k ( v ) \mathrm{link}(v) l i n k ( v ) q q q l i n k \mathrm{link} l i n k l i n k ( u ) = v \mathrm{link}(u) = v l i n k ( u ) = v l i n k \mathrm{link} l i n k 对于所有指向原先 q q q l e n ( v ) \mathrm{len}(v) l e n ( v ) v v v q q q
其他几个都很好处理,我们来考虑一下指向 v v v v v v p p p l i n k \mathrm{link} l i n k q q q v v v c c c q q q c c c q q q
SAM 的状态数上限为 2 n − 1 2n - 1 2 n − 1 2 2 2 1 + 1 + 1 + 2 × ( n − 2 ) = 2 n − 1 1 + 1 + 1 + 2 \times (n - 2) = 2n - 1 1 + 1 + 1 + 2 × ( n − 2 ) = 2 n − 1
SAM 的转移数上限为 3 n − 4 3n - 4 3 n − 4 2 n − 2 2n - 2 2 n − 2 s s s ( u , v ) (u, v) ( u , v ) u u u v v v 2 n − 2 + n − 2 = 3 n − 4 2n - 2 + n - 2 = 3n - 4 2 n − 2 + n − 2 = 3 n − 4
我们考虑构建 SAM 时的三种情况。O ( ∣ s ∣ ) O(\left|s\right|) O ( ∣ s ∣ ) O ( ∣ s ∣ ) O(\left|s\right|) O ( ∣ s ∣ ) O ( ∣ s ∣ ) O(\left|s\right|) O ( ∣ s ∣ ) O ( ∣ s ∣ ) O(\left|s\right|) O ( ∣ s ∣ )
注意实际应用中为了实现方便在第三种情况复制转移时一般会直接枚举所有 ∣ Σ ∣ \left|\Sigma\right| ∣ Σ ∣ O ( ∣ s ∣ ∣ Σ ∣ ) O(\left|s\right| \left|\Sigma\right|) O ( ∣ s ∣ ∣ Σ ∣ )
另外,对于字符集很大的情况,可以使用 map 来实现,时间复杂度变为 O ( ∣ s ∣ log ∣ Σ ∣ ) O(\left|s\right| \log \left|\Sigma\right|) O ( ∣ s ∣ log ∣ Σ ∣ )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 struct SAM { int tot, lst; int len[2000005 ], link[2000005 ]; int delta[2000005 ][26 ]; SAM () {link[0 ] = -1 ;} void insert (char ch) int c = ch - 'a' , now = ++tot; len[now] = len[lst] + 1 ; for (int p = lst; p != -1 ; p = link[p]) if (!delta[p][c]) delta[p][c] = tot; else if (len[delta[p][c]] == len[p] + 1 ) {link[now] = delta[p][c]; break ;} else { int q = delta[p][c], v = ++tot; len[v] = len[p] + 1 ; memcpy (delta[v], delta[q], sizeof (delta[v])); link[v] = link[q], link[q] = v, link[now] = v; for (int i = p; delta[i][c] == q; i = link[i]) delta[i][c] = v; break ; } lst = now; return ; } } sam;
相当于求其 e n d p o s \mathrm{endpos} e n d p o s l i n k \mathrm{link} l i n k l i n k \mathrm{link} l i n k l e n \mathrm{len} l e n
例题:洛谷 P3804【模板】后缀自动机(SAM) 。
答案为每个等价类的大小,即:
∑ u l e n ( u ) − l e n ( l i n k ( u ) ) \sum\limits_u \mathrm{len}(u) - \mathrm{len}(\mathrm{link}(u))
u ∑ l e n ( u ) − l e n ( l i n k ( u ) )
同样的方法也能求本质不同子串长度之和,即:
∑ u l e n ( u ) × ( l e n ( u ) + 1 ) 2 − l e n ( l i n k ( u ) ) × ( l e n ( l i n k ( u ) ) + 1 ) 2 \sum\limits_u \dfrac{\mathrm{len}(u) \times (\mathrm{len}(u) + 1)}{2} - \dfrac{\mathrm{len}(\mathrm{link}(u)) \times (\mathrm{len}(\mathrm{link}(u)) + 1)}{2}
u ∑ 2 l e n ( u ) × ( l e n ( u ) + 1 ) − 2 l e n ( l i n k ( u ) ) × ( l e n ( l i n k ( u ) ) + 1 )
例题:SDOI2016 生成魔咒 。
等价于在给每条边按边权排序后的第 k k k O ( a n s × ∣ Σ ∣ ) O(ans \times \left|\Sigma\right|) O ( a n s × ∣ Σ ∣ )
注意当 k = 1 k = 1 k = 1
例题:TJOI2015 弦论 。
不妨设要求的是第一次出现的结尾所在的位置。
我们考虑构建 SAM 的过程。p r e ( s , i ) \mathrm{pre}(s, i) p r e ( s , i ) i i i v v v q q q
我们加强一下 l i n k \mathrm{link} l i n k
我们发现某个串的每次出现都对应一个以它为后缀的 s s s
一个串没有出现等价于其在 SAM 上最终转移到 n u l l \mathrm{null} n u l l n u l l \mathrm{null} n u l l
设这两个串分别为 s s s t t t
我们对 s s s t t t
具体来说,假设当前在状态 u u u p r e ( t , i ) \mathrm{pre}(t, i) p r e ( t , i ) l l l u u u t i + 1 t _ {i + 1} t i + 1 l ← l + 1 l \gets l + 1 l ← l + 1
否则,我们就要缩小当前匹配的串。我们发现状态 u u u u ← l i n k ( u ) u \gets \mathrm{link}(u) u ← l i n k ( u ) u = s t a r t u = start u = s t a r t δ ( u , t i + 1 ) ≠ n u l l \delta(u, t _ {i + 1}) \neq \mathrm{null} δ ( u , t i + 1 ) = n u l l
每次操作至多使 l l l 1 1 1
对于最短的串建 SAM,然后用其他串在上面跑两个串的算法,每次跑完对于每个状态取个历史最小值,然后再用后缀链接树上的儿子更新答案,即如果儿子有值则将该状态的答案设为 l e n \mathrm{len} l e n
例题:SPOJ LCS2 - Longest Common Substring II 。